语音识别
修订履历
| NO | 版本 | 修订内容 | 修订日期 |
|---|---|---|---|
| 1 | Ver1.0 | 新建 | 2026/06/29 |
本文档中的信息可能会因文档改进而在不事先通知的情况下变更。最新版请参阅本公司网站。
未经株式会社日昇科技书面许可,严禁以任何形式复制本文档。
1. 语音识别概要
语音识别技术也称为自动语音识别(Automatic Speech Recognition,ASR)。其目的是将人类语音中包含的词汇内容转换为计算机可处理的输入,例如键盘输入、二进制编码或字符串等。与说话人识别和说话人确认不同,后者识别或确认的是发声者是谁,而不是语音中包含的词汇内容。
本语音识别算法基于 OpenAI 设计的 Whisper。Whisper 是一种通用语音识别模型,使用大量多语言、多任务监督数据进行训练。在英语语音识别中,可实现接近人类水平的鲁棒性和准确率。同时,Whisper 还支持多语言语音识别、语音翻译、语言识别等任务。其架构采用简单的端到端方式,使用编码器-解码器型 Transformer 模型,将输入语音转换为对应的文本序列,并通过特殊 token 指定不同任务。
在 CSUN RV1126B 基板上的运行效率如下:
| 算法类型 | 模型大小 | Real Time Factor (RTF) |
| speech_decoder | 383MB | 0.156 |
| speech_encoder | 217MB | 0.156 |
2. 快速开始
2.1 开发环境准备
如果您是首次阅读本文档,请参考《入门指南/开发编译环境的准备与更新》,并按照相关步骤部署编译环境。
在 PC 端 Ubuntu 系统中执行 run 脚本,进入 Docker 开发环境。步骤如下:
cd ~/linuxshare/work/rv1126b/jp/embedded/images/develop_environment./run.sh 2204
图2-1 Docker 开发环境启动
2.2 源代码下载
在 Docker 开发环境中,创建用于保存源代码仓库的管理目录。
cd /opt/linuxshare/work/rv1126b/jp/AI/demo/ai-algorithm使用 git 工具,在管理目录中克隆远程仓库。
git clone https://github.com/csunltd/rv1126b-ai-toolkit.git※ 即使从 GitHub 网页下载,也请下载整个仓库。请不要只单独下载与本示例对应的目录。
※ 如果已经下载完成,可以跳过此步骤。
2.3 模型部署
要运行算法 Demo,首先需要下载语音识别算法模型。
下载链接:
https://dl.dragonwake.com/download/rv1126b/AI/demo/08_speech_recognition.zip
之后,请将下载的语音识别算法模型复制到 Release/ 目录。
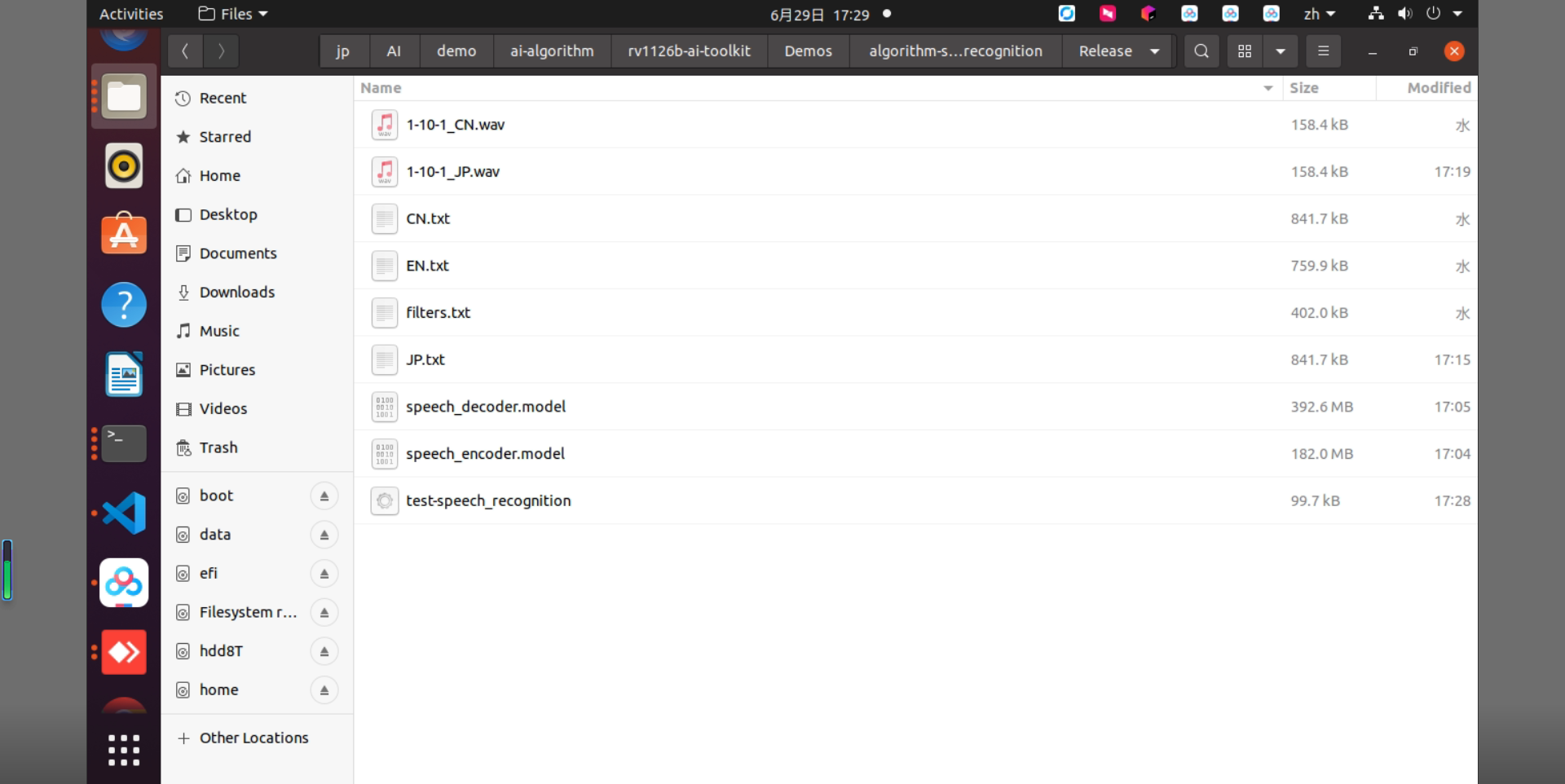
图2-2 Release 目录内的文件配置
2.4 示例构建
进入示例所在目录并执行构建。具体命令如下:
cd rv1126b-ai-toolkit/Demos/algorithm-speech_recognition/./build.sh cpres* 依赖库已配置在开发板上,因此交叉编译过程中需要保持 /mnt 挂载。
sudo mount -t nfs -o vers=3,proto=tcp,mountproto=tcp,nolock,retrans=5,timeo=5 192.168.10.85:/ /mnt* 为 build.sh 脚本指定 cpres 参数后,Release/ 目录内的所有资源都会被复制到开发板。
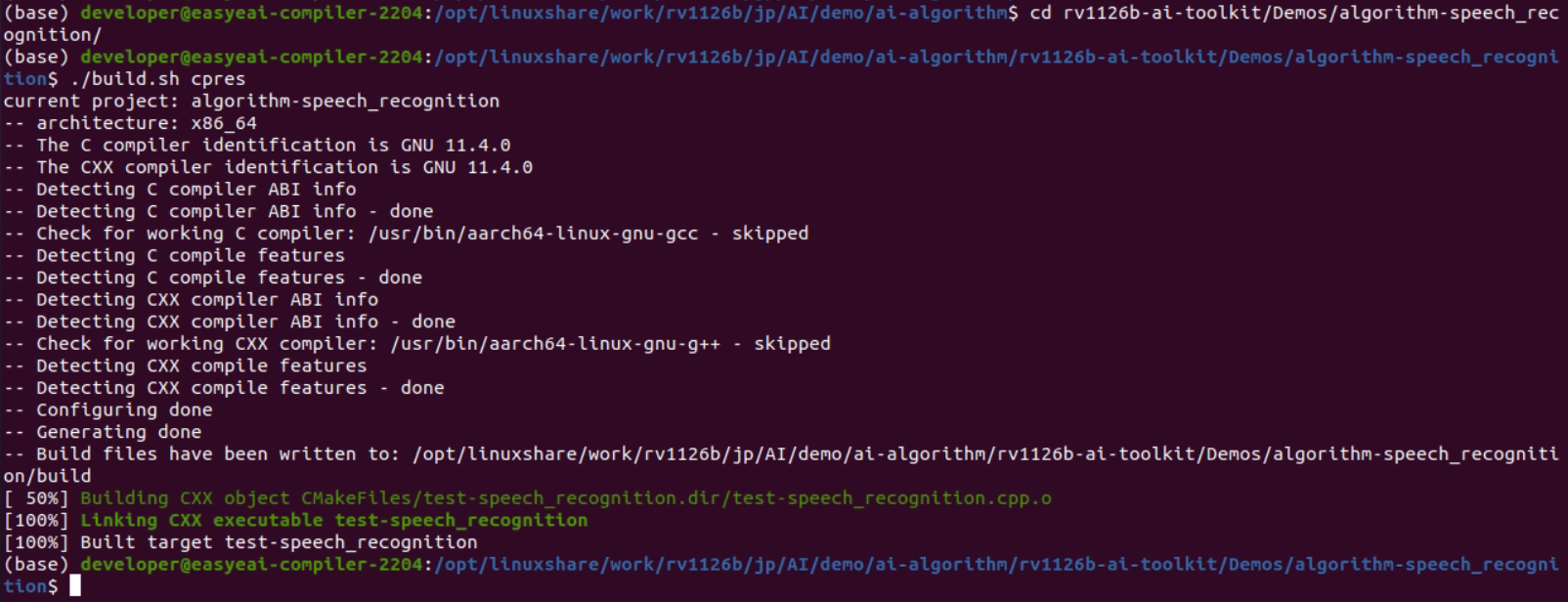
图2-3 开发板上的 Release 目录
2.5 示例运行及结果
将已编译的文件复制到基板。
cp Release/\* /mnt/userdata/Demo/algorithm-speech_recognition/※ 如果使用 ./build.sh cpres 编译,会自动复制。
通过串口调试或 SSH 调试进入开发板后台,并按如下方式移动到示例部署目录。
cd /userdata/Demo/algorithm-speech_recognition/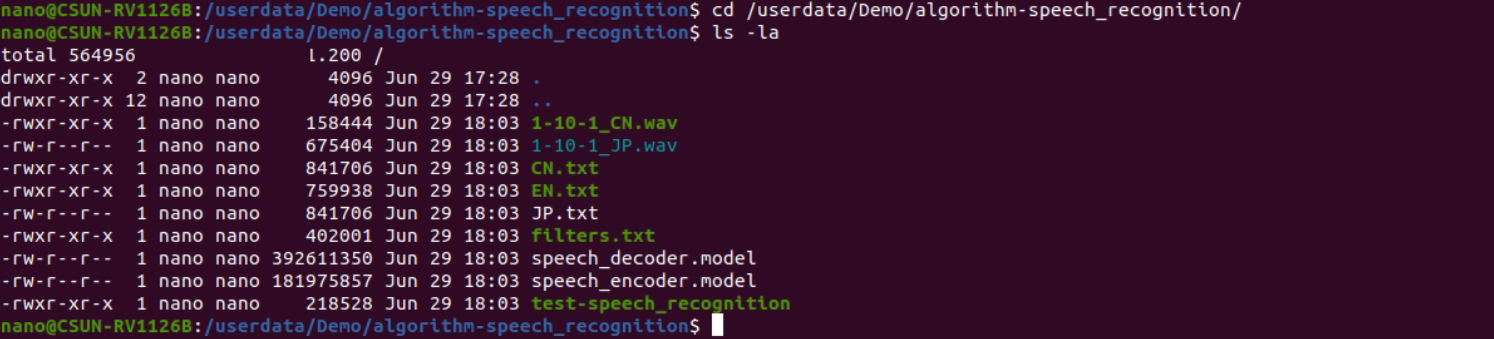
图2-4 示例构建结果
示例执行命令如下。
./test-speech_recognition speech_encoder.model speech_decoder.model filters.txt JP.txt ja 1-10-1_JP.wav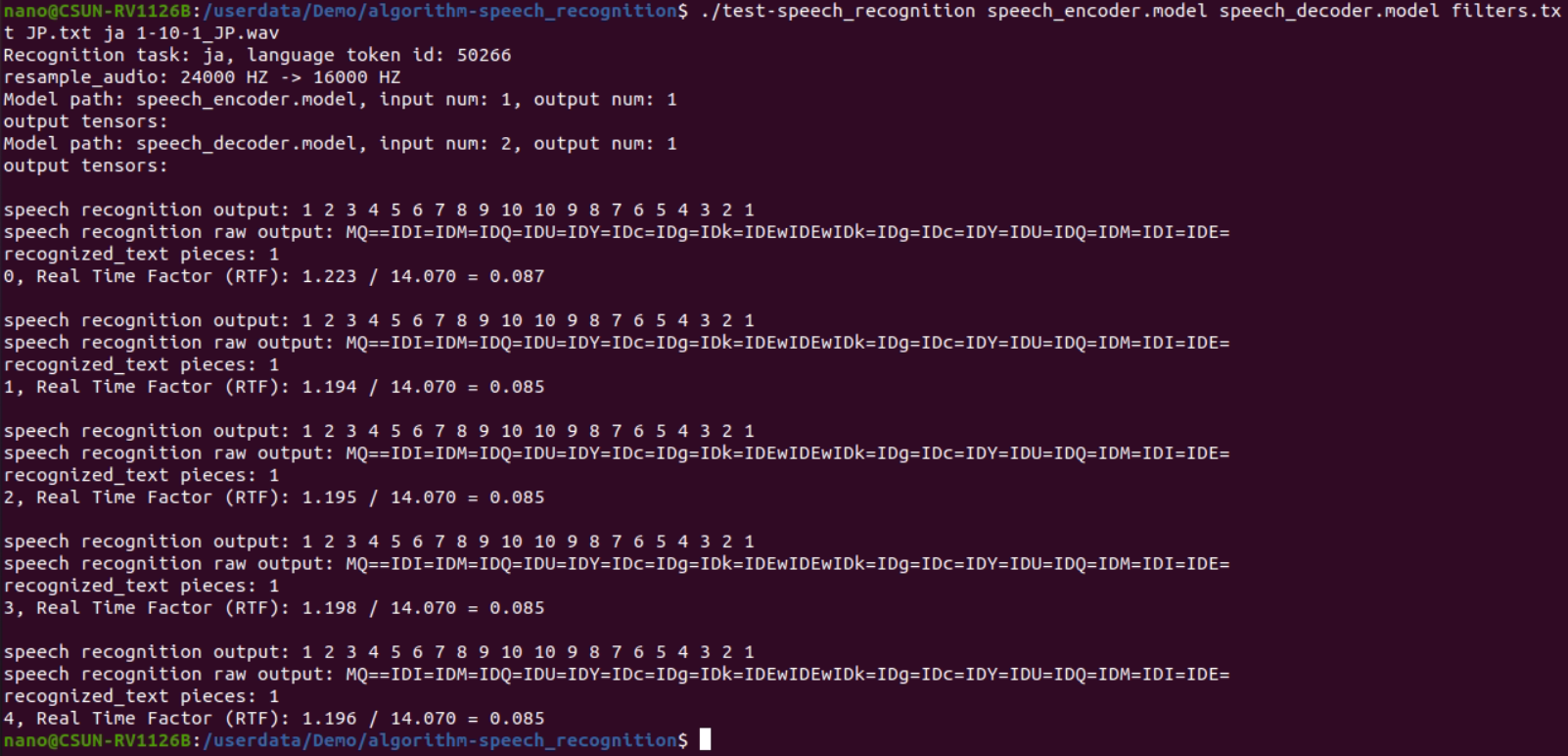
图2-5 语音识别执行结果
上述识别结果全部正确。
关于 API 的详细说明以及 API 调用方式(本示例的源代码),请参见以下内容。
3. 车辆检测API 说明
3.1 引用方法
为了使客户能够从本地项目中直接调用 EASY EAI API 库,本项目需要链接的库、头文件等如下所示。用户可以直接添加。
| 项目 | 说明 |
| 头文件目录 | easyeai-api/algorithm/speech_recognition |
| 库文件目录 | easyeai-api/algorithm/speech_recognition |
| 库链接参数 | -lspeech_recognition |
3.2 语音识别检测初始化函数
设置语音识别初始化函数原型如下。
int speech_recognition_init(const char \*p_encoder_path, const char \*p_decoder_path, const char \*p_filter_path,const char *p_vocab_path, rknn_whisper_t *p_whisper);
详细说明如下。
| 函数名: speech_recognition_init | |
| 头文件 | speech_recognition.h |
| 输入参数 | p_encoder_path:编码器模型名称/路径 |
| 输入参数 | p_decoder_path:解码器模型名称/路径 |
| 输入参数 | p_filter_path:滤波器频谱 |
| 输入参数 | p_vocab_path:词表文件 |
| 输入参数 | p_whisper:语音识别句柄 |
| 返回值 | 成功时返回值:0 |
| 失败时返回值:-1 | |
| 注意事项 | 无 |
3.3 语音识别执行函数
设置语音识别执行原型如下。
int speech_recognition_run(rknn_whisper_t \*p_whisper, audio_buffer_t audio, int task_code, std::vector\<std::string\> &recognized_text);详细说明如下。
| 函数名: speech_recognition_run | |
| 头文件 | speech_recognition.h |
| 输入参数 | p_whisper:语音识别句柄 |
| 输入参数 | audio:识别目标音频信息 |
| 输入参数 | task_code:语音识别任务 |
| 输入参数 | recognized_text:语音识别结果 |
| 返回值 | 成功时返回值:0 |
| 失败时返回值:-1 | |
| 注意事项 | 无 |
3.4 语音识别释放函数
设置语音识别释放原型如下。
int speech_recognition_release(rknn_whisper_t \*p_whisper);详细说明如下。
| 函数名:speech_recognition_release | |
| 头文件 | speech_recognition.h |
| 输入参数 | p_whisper:语音识别句柄 |
| 返回值 | 成功时返回值:0 |
| 失败时返回值:-1 | |
| 注意事项 | 无 |
4. 语音识别算法示例
示例目录为Demos/algorithm-speech_recognition/test-speech_recognition.cpp、操作流程如下:
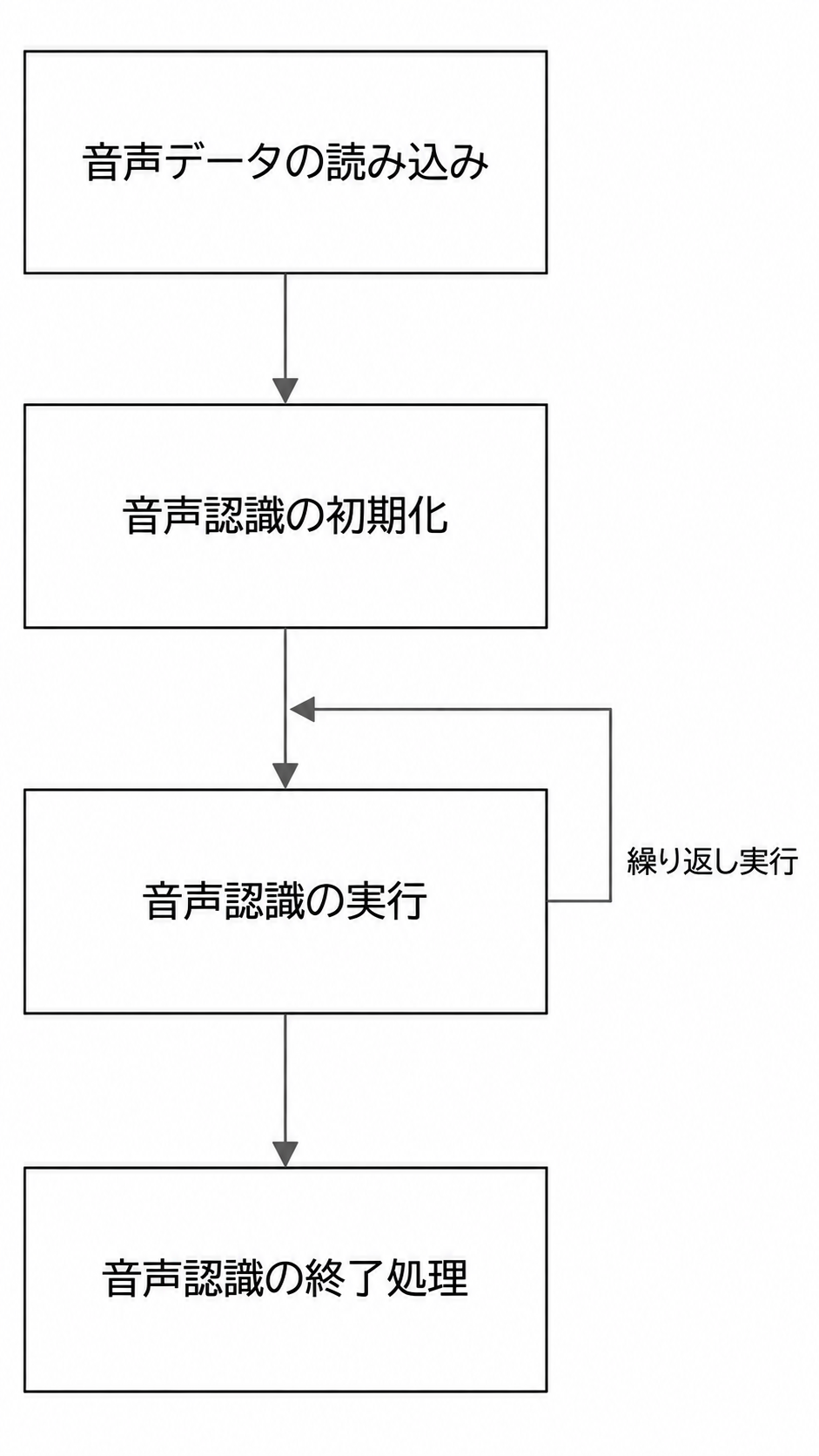
图4-1 语音识别算法处理流程
参考示例如下。
#include <iostream>#include <stdlib.h>#include <stdio.h>#include <string.h>#include <time.h>#include <string>#include <vector>#include <fstream>#include <sstream>#include <unordered_set>#include <unordered_map>#include <algorithm>#include "sndfile.h"#include "speech_recognition.h"#include "audio_utils.h"
static bool is_base64_char(char c){ return (c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '+' || c == '/' || c == '=';}
static bool looks_like_base64_token(const std::string &input){ if (input.empty() || (input.size() % 4) != 0){ return false; } for (char c : input){ if (!is_base64_char(c)){ return false; } } return true;}
static std::string base64_decode_token(const std::string &input, bool *ok){ static const std::string table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; std::string out; int val = 0; int valb = -8;
if (!looks_like_base64_token(input)){ *ok = false; return input; }
for (unsigned char c : input){ if (c == '='){ break; } int d = (int)table.find(c); if (d == (int)std::string::npos){ *ok = false; return input; } val = (val << 6) + d; valb += 6; if (valb >= 0){ out.push_back(char((val >> valb) & 0xFF)); valb -= 8; } } *ok = true; return out;}
static std::string trim_copy(const std::string &s){ size_t b = s.find_first_not_of(" \t\r\n"); if (b == std::string::npos){ return ""; } size_t e = s.find_last_not_of(" \t\r\n"); return s.substr(b, e - b + 1);}
static bool load_base64_vocab_tokens(const char *vocab_path, std::unordered_set<std::string> &token_set, std::vector<size_t> &token_lengths){ std::ifstream ifs(vocab_path); if (!ifs.is_open()){ return false; }
std::string line; std::unordered_set<size_t> length_set; while (std::getline(ifs, line)){ line = trim_copy(line); if (line.empty()){ continue; }
// Expected format: "<id> <token>". Keep compatibility with token-only lines too. std::string token; size_t pos = line.find_first_of(" \t"); if (pos == std::string::npos){ token = line; } else{ token = trim_copy(line.substr(pos + 1)); }
// Skip Whisper special tokens such as <|ja|> and non-base64 plain tokens. if (looks_like_base64_token(token)){ token_set.insert(token); length_set.insert(token.size()); } }
token_lengths.assign(length_set.begin(), length_set.end()); std::sort(token_lengths.begin(), token_lengths.end(), std::greater<size_t>()); return !token_set.empty();}
static bool decode_concatenated_base64_vocab(const std::string &input, const std::unordered_set<std::string> &token_set, const std::vector<size_t> &token_lengths, std::string &decoded_output){ decoded_output.clear(); if (input.empty() || token_set.empty() || token_lengths.empty()){ return false; }
size_t pos = 0; bool decoded_any = false;
while (pos < input.size()){ bool matched = false;
for (size_t len : token_lengths){ if (pos + len > input.size()){ continue; } std::string piece = input.substr(pos, len); if (token_set.find(piece) != token_set.end()){ bool ok = false; std::string decoded = base64_decode_token(piece, &ok); if (ok){ decoded_output += decoded; pos += len; matched = true; decoded_any = true; break; } } }
if (!matched){ // If the raw output contains non-base64 plain text, preserve it instead of failing hard. decoded_output.push_back(input[pos]); pos++; } }
return decoded_any;}
static std::string build_raw_output_text(const std::vector<std::string> &recognized_text){ std::string raw; for (const auto &str : recognized_text){ raw += str; } return raw;}
static std::string build_output_text(const std::vector<std::string> &recognized_text, bool decode_base64_vocab, const std::unordered_set<std::string> &token_set, const std::vector<size_t> &token_lengths){ if (!decode_base64_vocab){ return build_raw_output_text(recognized_text); }
std::string output;
// Case 1: recognized_text keeps token boundaries. Decode each token independently. if (recognized_text.size() > 1){ for (const auto &str : recognized_text){ bool ok = false; std::string decoded = base64_decode_token(str, &ok); output += ok ? decoded : str; } return output; }
// Case 2: speech_recognition_run has already concatenated Base64 token strings // into one string, such as "MQ==Mg==Mw==". Decode by matching against the vocab. std::string raw = build_raw_output_text(recognized_text); std::string decoded_concat; if (decode_concatenated_base64_vocab(raw, token_set, token_lengths, decoded_concat)){ return decoded_concat; }
// Fallback: try to decode it as a single Base64 token. bool ok = false; std::string decoded = base64_decode_token(raw, &ok); return ok ? decoded : raw;}
int main(int argc, char **argv){ if (argc != 6 && argc != 7){ printf("%s <encoder_path> <decoder_path> <filter_path> <vocab_path> [task(en/cn/zh/ja/jp)] <audio_path>\n", argv[0]); printf("Default task: ja (Japanese recognition)\n"); printf("Example default Japanese: %s speech_encoder.model speech_decoder.model filters.txt JP.txt 1-10-1_JP.wav\n", argv[0]); printf("Example Japanese: %s speech_encoder.model speech_decoder.model filters.txt JP.txt ja 1-10-1_JP.wav\n", argv[0]); printf("Example Chinese: %s speech_encoder.model speech_decoder.model filters.txt CN.txt cn 1-10-1_CN.wav\n", argv[0]); printf("Example English: %s speech_encoder.model speech_decoder.model filters.txt EN.txt en sample_EN.wav\n", argv[0]); return -1; }
const char *p_encoder_path = argv[1]; // エンコーダモデルパス const char *p_decoder_path = argv[2]; // デコーダモデルパス const char *p_filter_path = argv[3]; // フィルタスペクトル const char *p_vocab_path = argv[4]; // 語彙ファイル const char *p_task = "ja"; // 認識言語(デフォルト:ja) const char *p_audio_path = NULL; // 認識対象音声
if (argc == 6){ p_audio_path = argv[5]; } else{ p_task = argv[5]; p_audio_path = argv[6]; }
int task_code = 0; std::vector<std::string> recognized_text; bool decode_base64_vocab = false;
// Tokenizer の事前定義制御シンボル(Whisper 言語トークン) if (strcmp(p_task, "en") == 0){ task_code = 50259; // <|en|> } else if (strcmp(p_task, "cn") == 0 || strcmp(p_task, "zh") == 0){ task_code = 50260; // <|zh|> decode_base64_vocab = true; } else if (strcmp(p_task, "ja") == 0 || strcmp(p_task, "jp") == 0){ task_code = 50266; // <|ja|> decode_base64_vocab = true; } else{ printf("\n\033[1;33mUnsupported recognition task: %s. Please specify <task> as en, cn/zh, or ja/jp. If omitted, ja is used by default.\033[0m\n", p_task); return -1; }
std::unordered_set<std::string> base64_token_set; std::vector<size_t> base64_token_lengths; if (decode_base64_vocab){ if (!load_base64_vocab_tokens(p_vocab_path, base64_token_set, base64_token_lengths)){ printf("\n\033[1;33mWarning: failed to load Base64 vocab tokens from %s. Output may remain encoded.\033[0m\n", p_vocab_path); } }
printf("Recognition task: %s, language token id: %d\n", p_task, task_code);
// 音声を読み込み、音声データを処理します audio_buffer_t audio; int ret = read_audio(p_audio_path, &audio); if (ret != 0){ printf("read audio fail! ret=%d audio_path=%s\n", ret, p_audio_path); return -1; } if (audio.num_channels == 2){ ret = convert_channels(&audio); } if (audio.sample_rate != SAMPLE_RATE){ ret = resample_audio(&audio, audio.sample_rate, SAMPLE_RATE); }
// speech recognition を初期化します rknn_whisper_t whisper; ret = speech_recognition_init(p_encoder_path, p_decoder_path, p_filter_path, p_vocab_path, &whisper); if (ret != 0){ printf("speech_recognition_init fail! ret=%d\n", ret); return -1; }
int iter = 0; for (int i = 0; i < 5; i++) { clock_t start = clock();
recognized_text.clear(); // speech recognition による音声認識 ret = speech_recognition_run(&whisper, audio, task_code, recognized_text); if (ret != 0){ printf("speech_recognition_run fail! ret=%d\n", ret); break; }
clock_t end = clock(); double infer_time = ((double)(end - start)) / CLOCKS_PER_SEC;
std::string raw_output_text = build_raw_output_text(recognized_text); std::string output_text = build_output_text(recognized_text, decode_base64_vocab, base64_token_set, base64_token_lengths);
// decoded output std::cout << "\nspeech recognition output: " << output_text << std::endl;
// raw output is useful for diagnosing Base64 vocab and decoder behavior. if (decode_base64_vocab){ std::cout << "speech recognition raw output: " << raw_output_text << std::endl; std::cout << "recognized_text pieces: " << recognized_text.size() << std::endl; }
float audio_length = audio.num_frames / (float)SAMPLE_RATE; // sec audio_length = audio_length > (float)CHUNK_LENGTH ? (float)CHUNK_LENGTH : audio_length; float rtf = infer_time / audio_length; printf("%d, Real Time Factor (RTF): %.3f / %.3f = %.3f\n", iter++, infer_time, audio_length, rtf); }
// speech recognition を解放します speech_recognition_release(&whisper); return 0;}