音声認識
修正履歴
| NO | バージョン | 修正内容 | 修正日 |
|---|---|---|---|
| 1 | Ver1.0 | 新規作成 | 2026/06/29 |
この文書の情報は、文書を改善するため、事前の通知なく変更されることがあります。最新版は弊社ホームページからご参照ください。
株式会社日昇テクノロジーの書面による許可のない複製は、いかなる形態においても厳重に禁じられています。
1. 音声認識概要
音声認識技術は、自動音声認識(Automatic Speech Recognition、ASR)とも呼ばれます。その目的は、人間の音声に含まれる語彙内容を、キー入力、バイナリエンコード、文字列など、コンピュータが処理可能な入力へ変換することです。話者識別や話者確認とは異なり、後者は音声に含まれる語彙内容ではなく、発話者が誰であるかを識別または確認します。
本音声認識アルゴリズムは、OpenAIが設計したWhisperをベースとしています。Whisperは汎用的な音声認識モデルであり、大量の多言語・マルチタスクの教師ありデータで学習されています。英語音声認識では、人間に近いレベルのロバスト性と精度を実現できます。また、Whisperは多言語音声認識、音声翻訳、言語識別などのタスクにも対応しています。アーキテクチャはシンプルなエンドツーエンド方式で、エンコーダ・デコーダ型Transformerモデルを採用し、入力音声を対応するテキスト系列へ変換します。特殊トークンによって異なるタスクを指定します。
CSUN RV1126B基板での実行効率:
| アルゴリズム種別 | モデルサイズ | Real Time Factor (RTF) |
| speech_decoder | 383MB | 0.156 |
| speech_encoder | 217MB | 0.156 |
2. クイックスタート
2.1 開発環境の準備
本ドキュメントを初めてお読みになる場合は、『入門ガイド/開発コンパイル環境の準備と更新』を参照し、関連する手順に従ってコンパイル環境をデプロイしてください。
PC側のUbuntuシステムで run スクリプトを実行し、Docker開発環境に入ります。手順は次のとおりです。
cd ~/linuxshare/work/rv1126b/jp/embedded/images/develop_environment./run.sh 2204
図2-1 Docker開発環境の起動
2.2 ソースコードのダウンロード
Docker開発環境で、ソースコードリポジトリを保存する管理ディレクトリを作成します。
cd /opt/linuxshare/work/rv1126b/jp/AI/demo/ai-algorithmgitツールを使用して、管理ディレクトリ内にリモートリポジトリをクローンします。
git clone https://github.com/csunltd/rv1126b-ai-toolkit.git※GitHubのWebページからダウンロードする場合でも、リポジトリ全体をダウンロードしてください。本サンプルに対応するディレクトリだけを単独でダウンロードしないでください。
※すでにダウンロードした場合、飛ばしてください。
2.3 モデルデプロイ
アルゴリズムDemoを実行するには、まず音声認識アルゴリズムモデルをダウンロードする必要があります。
ダウンロードリンク:
https://dl.dragonwake.com/download/rv1126b/AI/demo/08_speech_recognition.zip
その後、ダウンロードした音声認識アルゴリズムモデルを Release/ ディレクトリへコピーしてください。
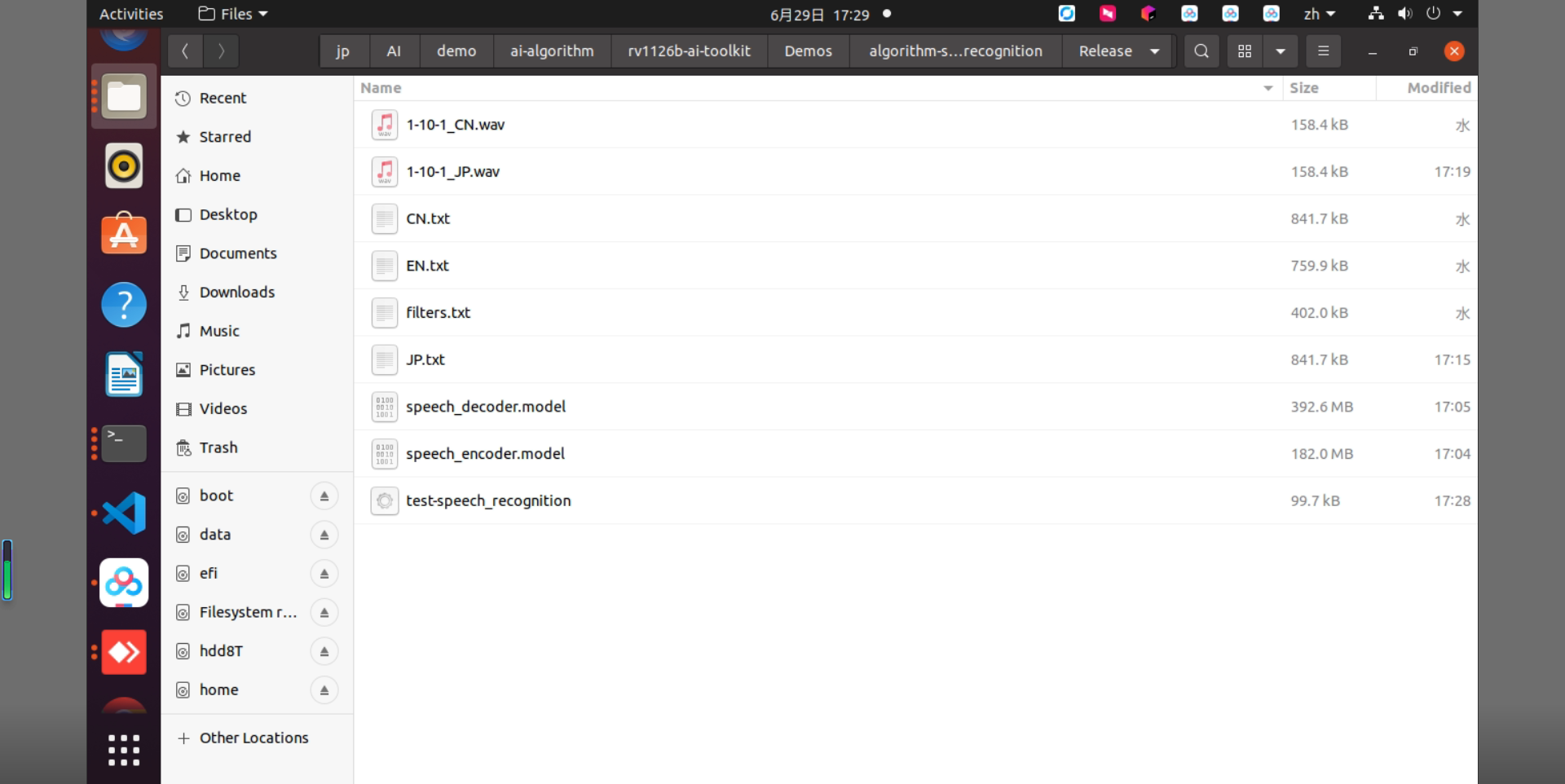
図2-2 Releaseディレクトリ内のファイル配置
2.4 サンプルのビルド
サンプルがあるディレクトリに移動してビルドを実行します。具体的なコマンドは次のとおりです。
cd rv1126b-ai-toolkit/Demos/algorithm-speech_recognition/./build.sh cpres* 依存ライブラリは開発ボード上に配置されているため、クロスコンパイル中は /mnt のマウントを保持する必要があります。
sudo mount -t nfs -o vers=3,proto=tcp,mountproto=tcp,nolock,retrans=5,timeo=5 192.168.10.85:/ /mnt* build.sh スクリプトに cpres パラメータを指定すると、Release/ ディレクトリ内のすべてのリソースが開発ボードへコピーされます。
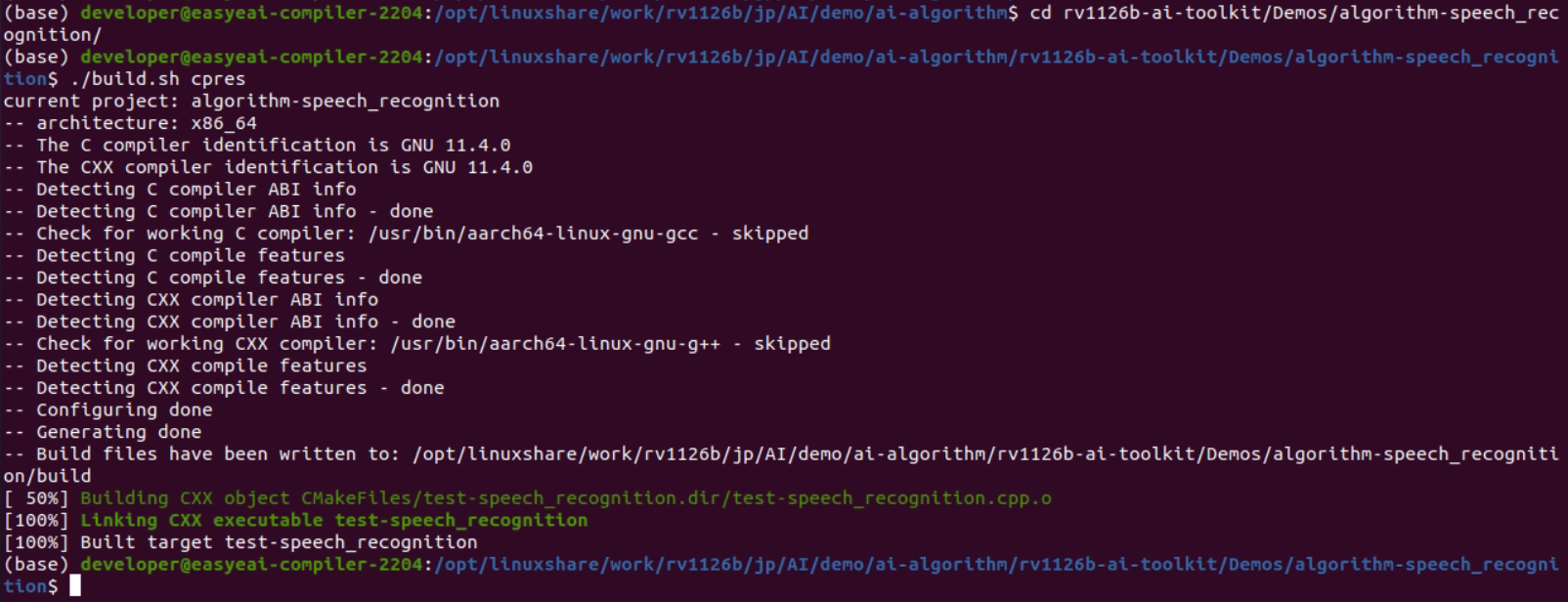
図2-3 開発ボード上のReleaseディレクトリ
2.5 サンプル実行および結果
コンパイル済みのものを基板にコピーします。
cp Release/\* /mnt/userdata/Demo/algorithm-speech_recognition/※./build.sh cpresでコンパイルした場合、自動的にコピーされます。
シリアルデバッグまたはSSHデバッグで開発ボードのバックエンドに入り、次のようにサンプルのデプロイ先へ移動します。
cd /userdata/Demo/algorithm-speech_recognition/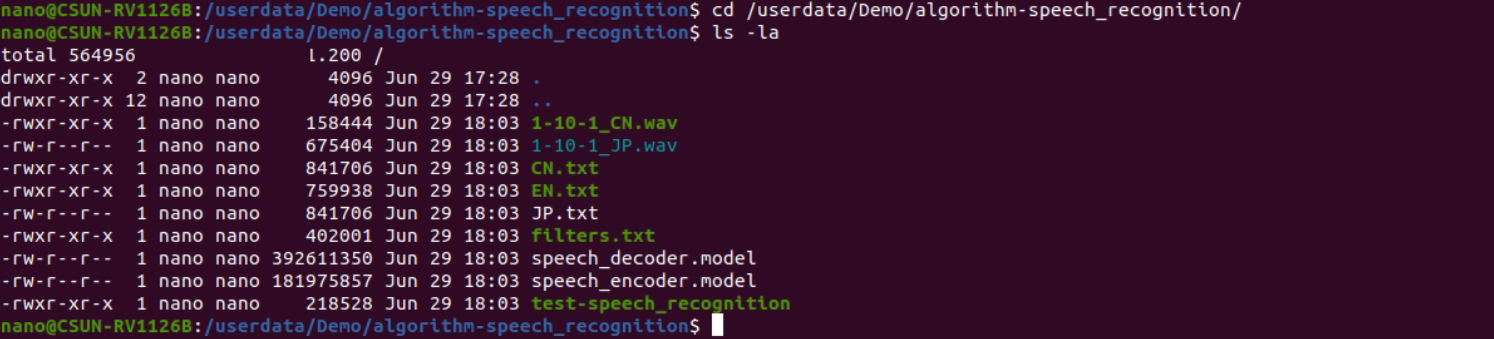
図2-4 サンプルビルド結果
サンプルの実行コマンドは次のとおりです。
./test-speech_recognition speech_encoder.model speech_decoder.model filters.txt JP.txt ja 1-10-1_JP.wav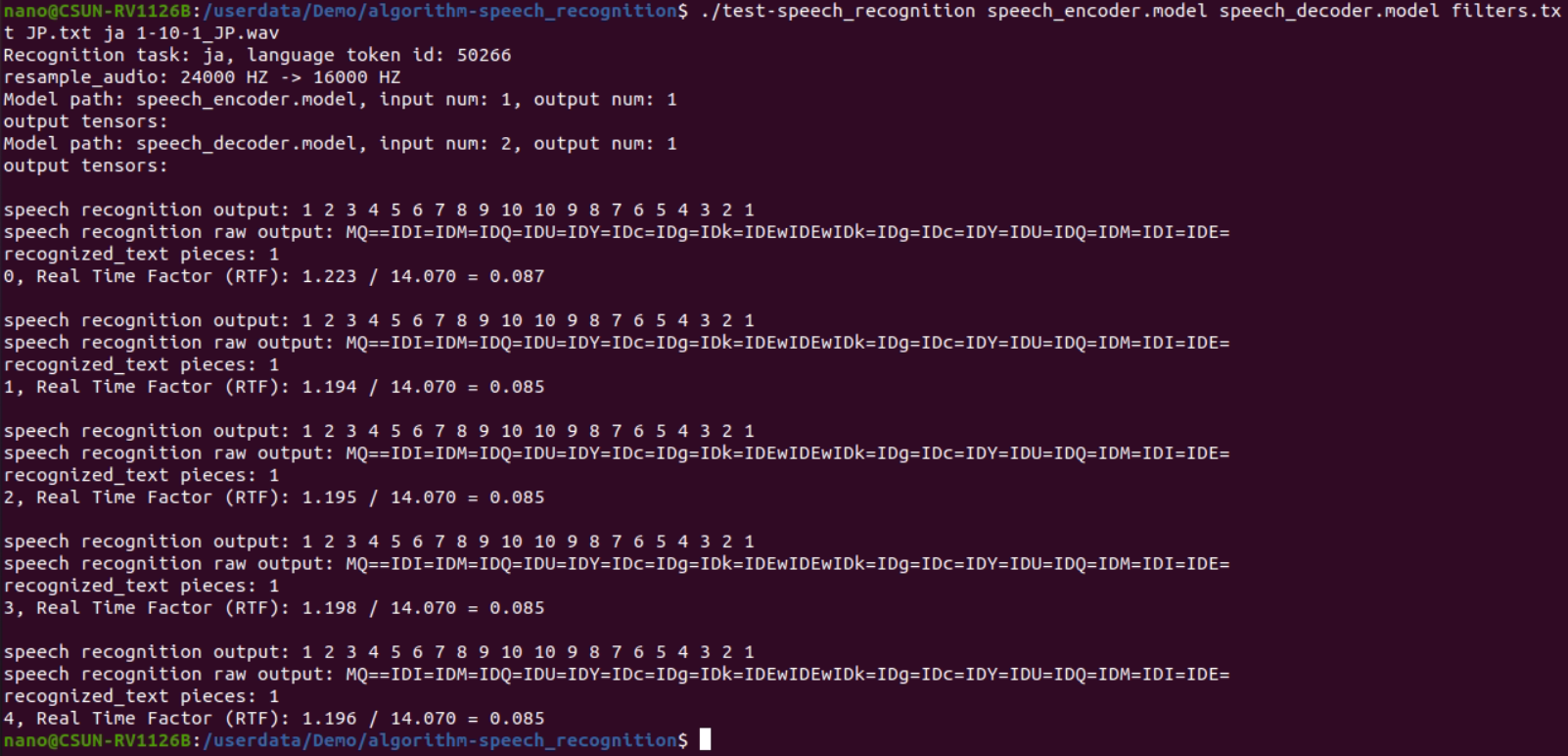
図2-5 音声認識実行結果
上記認識結果はすべて正しいです。
APIの詳細説明およびAPI呼び出し(本サンプルのソースコード)については、以下を参照してください。
3. 車両検出API説明
3.1 参照方法
お客様がローカルプロジェクトからEASY EAI APIライブラリを直接呼び出せるように、本プロジェクトでリンクする必必要がありますがあるライブラリおよびヘッダファイルなどを以下に示します。ユーザーはそのまま追加できます。
| 項目 | 説明 |
| ヘッダファイルディレクトリ | easyeai-api/algorithm/speech_recognition |
| ライブラリファイルディレクトリ | easyeai-api/algorithm/speech_recognition |
| ライブラリリンクパラメータ | -lspeech_recognition |
3.2 音声認識検出初期化関数
设置音声認識初期化関数原型次のとおりです。
int speech_recognition_init(const char \*p_encoder_path, const char \*p_decoder_path, const char \*p_filter_path,const char *p_vocab_path, rknn_whisper_t *p_whisper);
詳細は次のとおりです。
| 関数名: speech_recognition_init | |
| ヘッダファイル | speech_recognition.h |
| 入力パラメータ | p_encoder_path:エンコーダモデル名/パス |
| 入力パラメータ | p_decoder_path:デコーダモデル名/パス |
| 入力パラメータ | p_filter_path:フィルタスペクトル |
| 入力パラメータ | p_vocab_path:語彙ファイル |
| 入力パラメータ | p_whisper:音声認識ハンドル |
| 戻り値 | 成功時の戻り値:0 |
| 失敗時の戻り値:-1 | |
| 注意事項 | なし |
3.3 音声認識実行関数
设置音声認識実行原型次のとおりです。
int speech_recognition_run(rknn_whisper_t \*p_whisper, audio_buffer_t audio, int task_code, std::vector\<std::string\> &recognized_text);詳細は次のとおりです。
| 関数名: speech_recognition_run | |
| ヘッダファイル | speech_recognition.h |
| 入力パラメータ | p_whisper:音声認識ハンドル |
| 入力パラメータ | audio:認識対象音声情報 |
| 入力パラメータ | task_code:音声認識タスク |
| 入力パラメータ | recognized_text:音声認識結果 |
| 戻り値 | 成功時の戻り値:0 |
| 失敗時の戻り値:-1 | |
| 注意事項 | なし |
3.4 音声認識解放関数
设置音声認識解放原型次のとおりです。
int speech_recognition_release(rknn_whisper_t \*p_whisper);詳細は次のとおりです。
| 関数名:speech_recognition_release | |
| ヘッダファイル | speech_recognition.h |
| 入力パラメータ | p_whisper:音声認識ハンドル |
| 戻り値 | 成功時の戻り値:0 |
| 失敗時の戻り値:-1 | |
| 注意事項 | なし |
4. 音声認識アルゴリズムサンプル
サンプルディレクトリとしてDemos/algorithm-speech_recognition/test-speech_recognition.cpp、操作フロー次のとおりです:
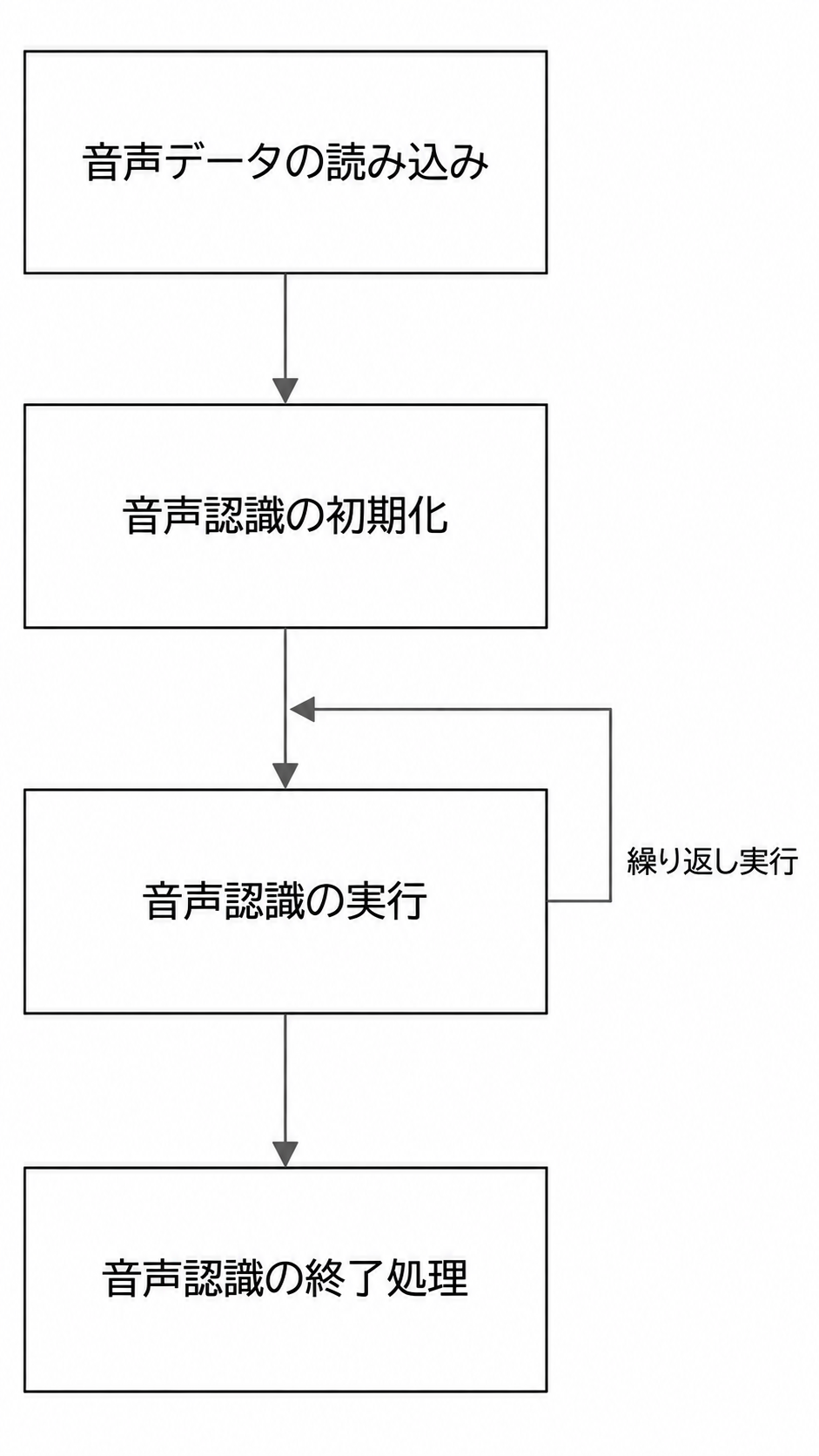
図4-1 音声認識アルゴリズム処理フロー
参考サンプルは次のとおりです。
#include <iostream>#include <stdlib.h>#include <stdio.h>#include <string.h>#include <time.h>#include <string>#include <vector>#include <fstream>#include <sstream>#include <unordered_set>#include <unordered_map>#include <algorithm>#include "sndfile.h"#include "speech_recognition.h"#include "audio_utils.h"
static bool is_base64_char(char c){ return (c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '+' || c == '/' || c == '=';}
static bool looks_like_base64_token(const std::string &input){ if (input.empty() || (input.size() % 4) != 0){ return false; } for (char c : input){ if (!is_base64_char(c)){ return false; } } return true;}
static std::string base64_decode_token(const std::string &input, bool *ok){ static const std::string table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; std::string out; int val = 0; int valb = -8;
if (!looks_like_base64_token(input)){ *ok = false; return input; }
for (unsigned char c : input){ if (c == '='){ break; } int d = (int)table.find(c); if (d == (int)std::string::npos){ *ok = false; return input; } val = (val << 6) + d; valb += 6; if (valb >= 0){ out.push_back(char((val >> valb) & 0xFF)); valb -= 8; } } *ok = true; return out;}
static std::string trim_copy(const std::string &s){ size_t b = s.find_first_not_of(" \t\r\n"); if (b == std::string::npos){ return ""; } size_t e = s.find_last_not_of(" \t\r\n"); return s.substr(b, e - b + 1);}
static bool load_base64_vocab_tokens(const char *vocab_path, std::unordered_set<std::string> &token_set, std::vector<size_t> &token_lengths){ std::ifstream ifs(vocab_path); if (!ifs.is_open()){ return false; }
std::string line; std::unordered_set<size_t> length_set; while (std::getline(ifs, line)){ line = trim_copy(line); if (line.empty()){ continue; }
// Expected format: "<id> <token>". Keep compatibility with token-only lines too. std::string token; size_t pos = line.find_first_of(" \t"); if (pos == std::string::npos){ token = line; } else{ token = trim_copy(line.substr(pos + 1)); }
// Skip Whisper special tokens such as <|ja|> and non-base64 plain tokens. if (looks_like_base64_token(token)){ token_set.insert(token); length_set.insert(token.size()); } }
token_lengths.assign(length_set.begin(), length_set.end()); std::sort(token_lengths.begin(), token_lengths.end(), std::greater<size_t>()); return !token_set.empty();}
static bool decode_concatenated_base64_vocab(const std::string &input, const std::unordered_set<std::string> &token_set, const std::vector<size_t> &token_lengths, std::string &decoded_output){ decoded_output.clear(); if (input.empty() || token_set.empty() || token_lengths.empty()){ return false; }
size_t pos = 0; bool decoded_any = false;
while (pos < input.size()){ bool matched = false;
for (size_t len : token_lengths){ if (pos + len > input.size()){ continue; } std::string piece = input.substr(pos, len); if (token_set.find(piece) != token_set.end()){ bool ok = false; std::string decoded = base64_decode_token(piece, &ok); if (ok){ decoded_output += decoded; pos += len; matched = true; decoded_any = true; break; } } }
if (!matched){ // If the raw output contains non-base64 plain text, preserve it instead of failing hard. decoded_output.push_back(input[pos]); pos++; } }
return decoded_any;}
static std::string build_raw_output_text(const std::vector<std::string> &recognized_text){ std::string raw; for (const auto &str : recognized_text){ raw += str; } return raw;}
static std::string build_output_text(const std::vector<std::string> &recognized_text, bool decode_base64_vocab, const std::unordered_set<std::string> &token_set, const std::vector<size_t> &token_lengths){ if (!decode_base64_vocab){ return build_raw_output_text(recognized_text); }
std::string output;
// Case 1: recognized_text keeps token boundaries. Decode each token independently. if (recognized_text.size() > 1){ for (const auto &str : recognized_text){ bool ok = false; std::string decoded = base64_decode_token(str, &ok); output += ok ? decoded : str; } return output; }
// Case 2: speech_recognition_run has already concatenated Base64 token strings // into one string, such as "MQ==Mg==Mw==". Decode by matching against the vocab. std::string raw = build_raw_output_text(recognized_text); std::string decoded_concat; if (decode_concatenated_base64_vocab(raw, token_set, token_lengths, decoded_concat)){ return decoded_concat; }
// Fallback: try to decode it as a single Base64 token. bool ok = false; std::string decoded = base64_decode_token(raw, &ok); return ok ? decoded : raw;}
int main(int argc, char **argv){ if (argc != 6 && argc != 7){ printf("%s <encoder_path> <decoder_path> <filter_path> <vocab_path> [task(en/cn/zh/ja/jp)] <audio_path>\n", argv[0]); printf("Default task: ja (Japanese recognition)\n"); printf("Example default Japanese: %s speech_encoder.model speech_decoder.model filters.txt JP.txt 1-10-1_JP.wav\n", argv[0]); printf("Example Japanese: %s speech_encoder.model speech_decoder.model filters.txt JP.txt ja 1-10-1_JP.wav\n", argv[0]); printf("Example Chinese: %s speech_encoder.model speech_decoder.model filters.txt CN.txt cn 1-10-1_CN.wav\n", argv[0]); printf("Example English: %s speech_encoder.model speech_decoder.model filters.txt EN.txt en sample_EN.wav\n", argv[0]); return -1; }
const char *p_encoder_path = argv[1]; // エンコーダモデルパス const char *p_decoder_path = argv[2]; // デコーダモデルパス const char *p_filter_path = argv[3]; // フィルタスペクトル const char *p_vocab_path = argv[4]; // 語彙ファイル const char *p_task = "ja"; // 認識言語(デフォルト:ja) const char *p_audio_path = NULL; // 認識対象音声
if (argc == 6){ p_audio_path = argv[5]; } else{ p_task = argv[5]; p_audio_path = argv[6]; }
int task_code = 0; std::vector<std::string> recognized_text; bool decode_base64_vocab = false;
// Tokenizer の事前定義制御シンボル(Whisper 言語トークン) if (strcmp(p_task, "en") == 0){ task_code = 50259; // <|en|> } else if (strcmp(p_task, "cn") == 0 || strcmp(p_task, "zh") == 0){ task_code = 50260; // <|zh|> decode_base64_vocab = true; } else if (strcmp(p_task, "ja") == 0 || strcmp(p_task, "jp") == 0){ task_code = 50266; // <|ja|> decode_base64_vocab = true; } else{ printf("\n\033[1;33mUnsupported recognition task: %s. Please specify <task> as en, cn/zh, or ja/jp. If omitted, ja is used by default.\033[0m\n", p_task); return -1; }
std::unordered_set<std::string> base64_token_set; std::vector<size_t> base64_token_lengths; if (decode_base64_vocab){ if (!load_base64_vocab_tokens(p_vocab_path, base64_token_set, base64_token_lengths)){ printf("\n\033[1;33mWarning: failed to load Base64 vocab tokens from %s. Output may remain encoded.\033[0m\n", p_vocab_path); } }
printf("Recognition task: %s, language token id: %d\n", p_task, task_code);
// 音声を読み込み、音声データを処理します audio_buffer_t audio; int ret = read_audio(p_audio_path, &audio); if (ret != 0){ printf("read audio fail! ret=%d audio_path=%s\n", ret, p_audio_path); return -1; } if (audio.num_channels == 2){ ret = convert_channels(&audio); } if (audio.sample_rate != SAMPLE_RATE){ ret = resample_audio(&audio, audio.sample_rate, SAMPLE_RATE); }
// speech recognition を初期化します rknn_whisper_t whisper; ret = speech_recognition_init(p_encoder_path, p_decoder_path, p_filter_path, p_vocab_path, &whisper); if (ret != 0){ printf("speech_recognition_init fail! ret=%d\n", ret); return -1; }
int iter = 0; for (int i = 0; i < 5; i++) { clock_t start = clock();
recognized_text.clear(); // speech recognition による音声認識 ret = speech_recognition_run(&whisper, audio, task_code, recognized_text); if (ret != 0){ printf("speech_recognition_run fail! ret=%d\n", ret); break; }
clock_t end = clock(); double infer_time = ((double)(end - start)) / CLOCKS_PER_SEC;
std::string raw_output_text = build_raw_output_text(recognized_text); std::string output_text = build_output_text(recognized_text, decode_base64_vocab, base64_token_set, base64_token_lengths);
// decoded output std::cout << "\nspeech recognition output: " << output_text << std::endl;
// raw output is useful for diagnosing Base64 vocab and decoder behavior. if (decode_base64_vocab){ std::cout << "speech recognition raw output: " << raw_output_text << std::endl; std::cout << "recognized_text pieces: " << recognized_text.size() << std::endl; }
float audio_length = audio.num_frames / (float)SAMPLE_RATE; // sec audio_length = audio_length > (float)CHUNK_LENGTH ? (float)CHUNK_LENGTH : audio_length; float rtf = infer_time / audio_length; printf("%d, Real Time Factor (RTF): %.3f / %.3f = %.3f\n", iter++, infer_time, audio_length, rtf); }
// speech recognition を解放します speech_recognition_release(&whisper); return 0;}