Speech Recognition
Revision History
| NO | Version | Description | Date |
|---|---|---|---|
| 1 | Ver1.0 | Initial creation | 2026/06/29 |
The information in this document may be changed without prior notice for the purpose of improving the document. Please refer to our website for the latest version.
Reproduction in any form without the written permission of Nissho Technology Co., Ltd. is strictly prohibited.
1. Speech RecognitionOverview
Speech recognition technology is also called Automatic Speech Recognition (ASR). Its purpose is to convert the lexical content contained in human speech into computer-processable input, such as keystrokes, binary encoding, or strings. Unlike speaker identification and speaker verification, the latter identifies or verifies who the speaker is rather than the lexical content contained in the speech.
This speech recognition algorithm is based on Whisper designed by OpenAI. Whisper is a general-purpose speech recognition model trained on a large amount of multilingual and multitask supervised data. In English speech recognition, it can achieve near-human robustness and accuracy. Whisper also supports tasks such as multilingual speech recognition, speech translation, and language identification. Its architecture uses a simple end-to-end approach with an encoder-decoder Transformer model, converting input speech into the corresponding text sequence and specifying different tasks through special tokens.
The execution efficiency on the CSUN RV1126B board is as follows:
| Algorithm Type | Model Size | Real Time Factor (RTF) |
| speech_decoder | 383MB | 0.156 |
| speech_encoder | 217MB | 0.156 |
2. Quick Start
2.1 Preparing the Development Environment
If you are reading this document for the first time, refer to Getting Started / Preparing and Updating the Development Compilation Environment, and deploy the compilation environment according to the related steps.
On the Ubuntu system on the PC side, run the run script to enter the Docker development environment. The steps are as follows:
cd ~/linuxshare/work/rv1126b/jp/embedded/images/develop_environment./run.sh 2204
Figure 2-1 Starting the Docker Development Environment
2.2 Downloading the Source Code
In the Docker development environment, create a management directory for storing the source code repository.
cd /opt/linuxshare/work/rv1126b/jp/AI/demo/ai-algorithmUse the git tool to clone the remote repository into the management directory.
git clone https://github.com/csunltd/rv1126b-ai-toolkit.git※ Even when downloading from the GitHub web page, download the entire repository. Do not download only the directory corresponding to this sample.
※ If the repository has already been downloaded, skip this step.
2.3 Model Deployment
To run the algorithm Demo, first download the speech recognition algorithm model.
Download link:
https://dl.dragonwake.com/download/rv1126b/AI/demo/08_speech_recognition.zip
Then copy the downloaded speech recognition algorithm model to the Release/ directory.
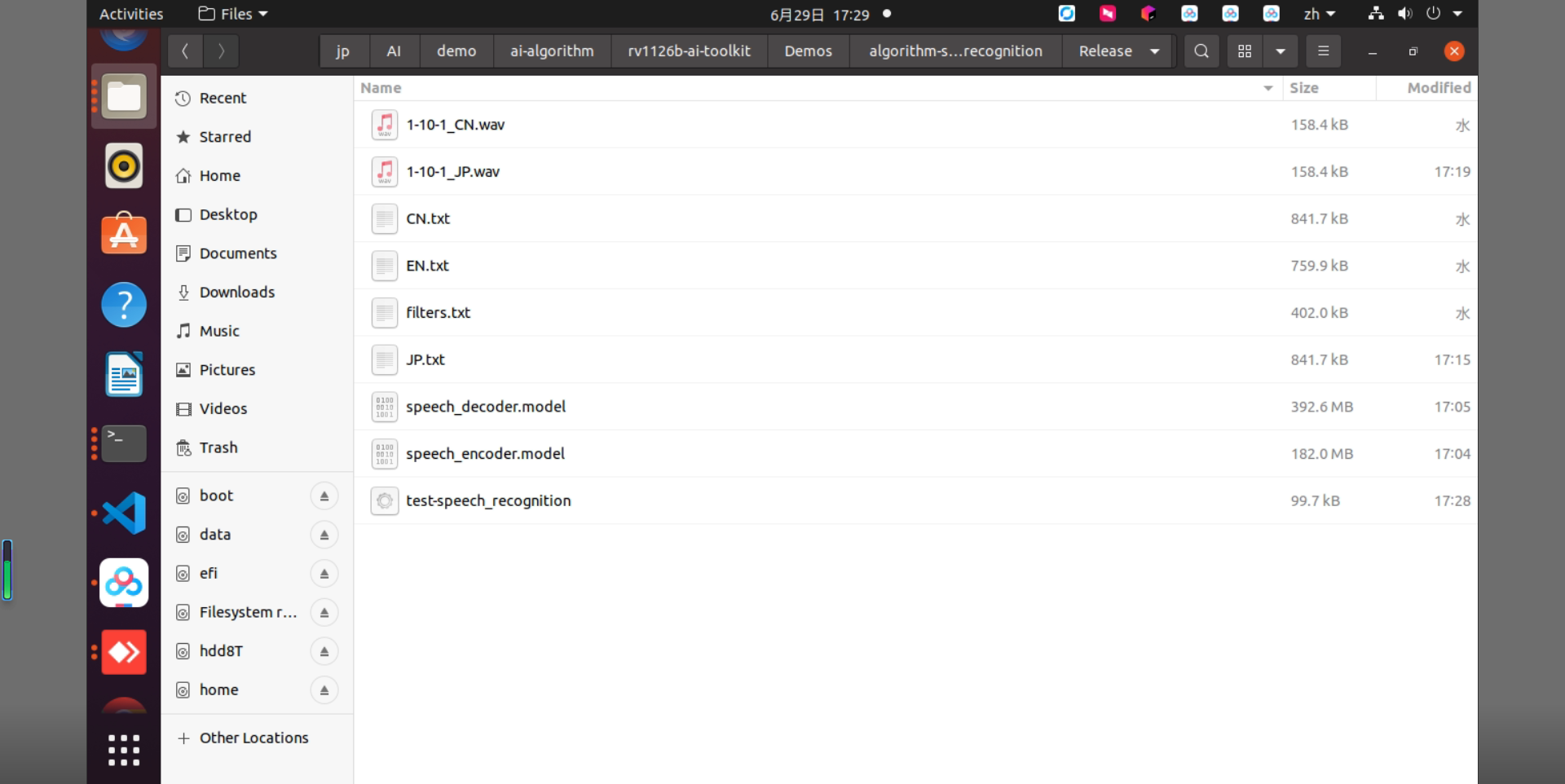
Figure 2-2 Files in the Release Directory
2.4 Building the Sample
Move to the directory containing the sample and execute the build. The specific commands are as follows:
cd rv1126b-ai-toolkit/Demos/algorithm-speech_recognition/./build.sh cpres* Because the dependent libraries are located on the development board, keep /mnt mounted during cross-compilation.
sudo mount -t nfs -o vers=3,proto=tcp,mountproto=tcp,nolock,retrans=5,timeo=5 192.168.10.85:/ /mnt* When the cpres parameter is specified for the build.sh script, all resources in the Release/ directory are copied to the development board.
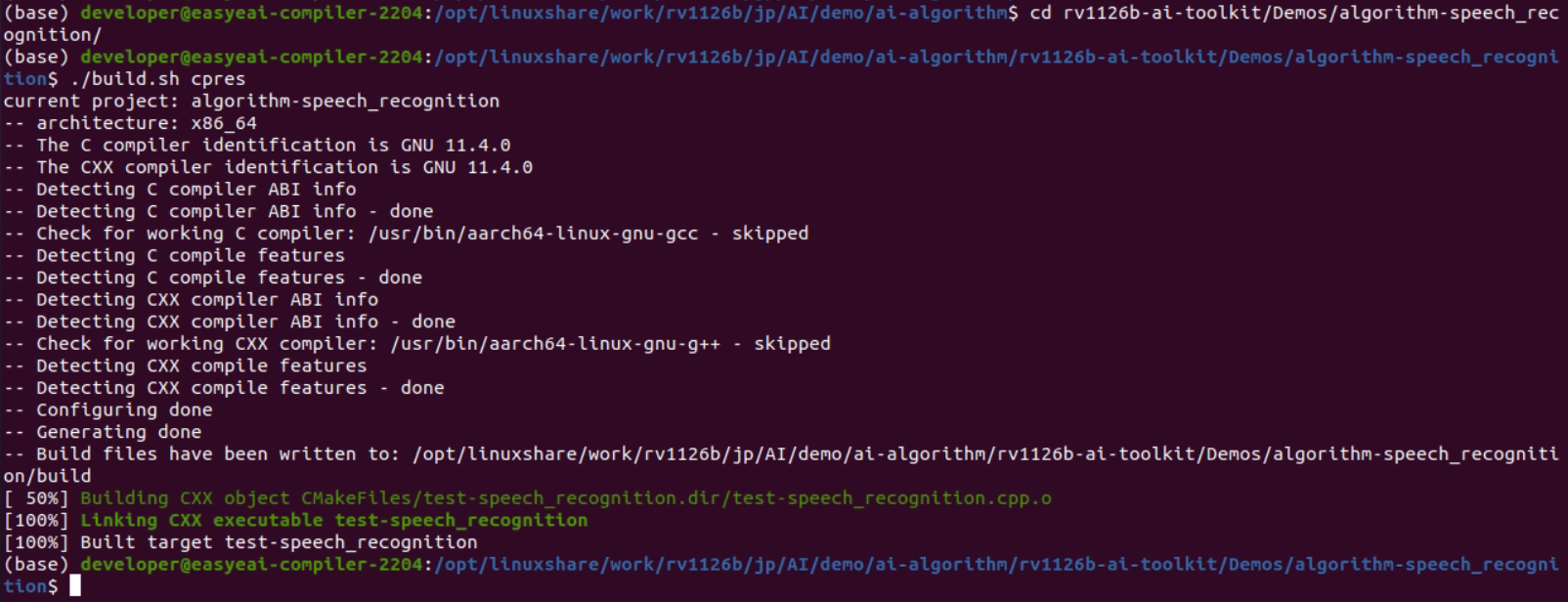
Figure 2-3 Release Directory on the Development Board
2.5 Sample Execution and Results
Copy the compiled files to the board.
cp Release/\* /mnt/userdata/Demo/algorithm-speech_recognition/※ If you build with ./build.sh cpres, the files are copied automatically.
Enter the backend of the development board through serial debugging or SSH debugging, and move to the sample deployment directory as follows:
cd /userdata/Demo/algorithm-speech_recognition/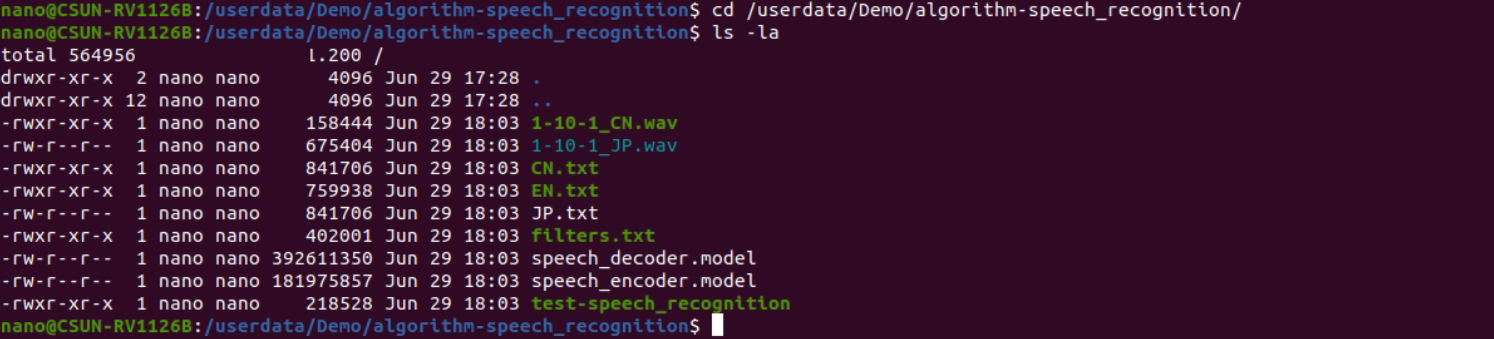
Figure 2-4 Sample Build Result
The sample execution command is as follows.
./test-speech_recognition speech_encoder.model speech_decoder.model filters.txt JP.txt ja 1-10-1_JP.wav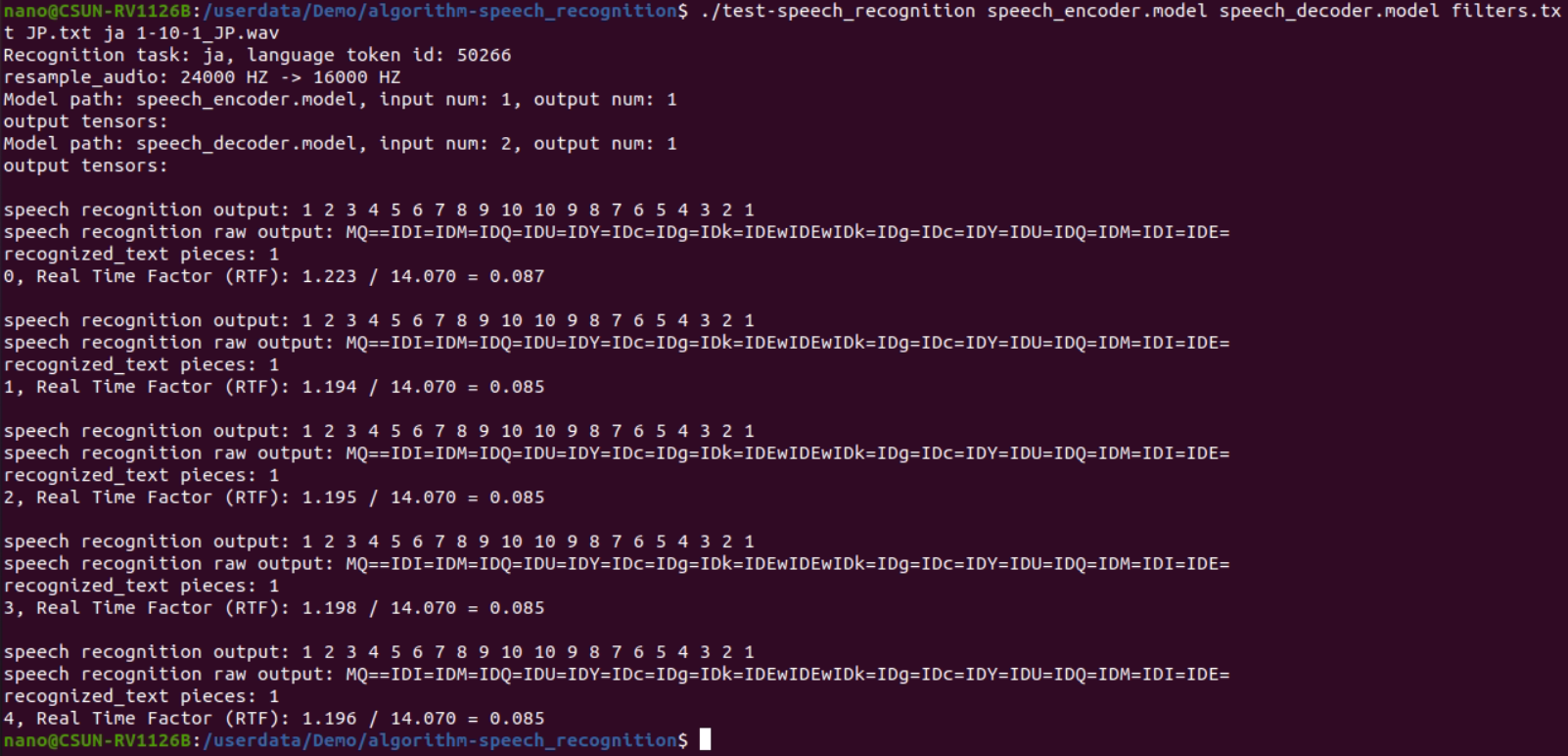
Figure 2-5 Speech RecognitionexecutionResult
All of the above recognition results are correct.
For detailed API descriptions and API calls (the source code of this sample), refer to the following.
3. Vehicle DetectionAPI Description
3.1 Reference Method
To allow users to call the EASY EAI API library directly from a local project, the libraries and header files that need to be linked in this project are listed below. Users can add them directly.
| Item | Description |
| Header File Directory | easyeai-api/algorithm/speech_recognition |
| Library File Directory | easyeai-api/algorithm/speech_recognition |
| Library Link Parameter | -lspeech_recognition |
3.2 Speech RecognitiondetectionInitialization Function
The speech recognition initialization function prototype is as follows.
int speech_recognition_init(const char \*p_encoder_path, const char \*p_decoder_path, const char \*p_filter_path,const char *p_vocab_path, rknn_whisper_t *p_whisper);
The details are as follows.
| Function Name: speech_recognition_init | |
| Header File | speech_recognition.h |
| Input Parameter | p_encoder_path: encoder model name/path |
| Input Parameter | p_decoder_path: decoder model name/path |
| Input Parameter | p_filter_path:filter spectrum |
| Input Parameter | p_vocab_path:vocabulary file |
| Input Parameter | p_whisper: speech recognition handle |
| Return Value | Return value on success: 0 |
| Return value on failure: -1 | |
| Notes | None |
3.3 Speech RecognitionExecution Function
The speech recognition execution function prototype is as follows.
int speech_recognition_run(rknn_whisper_t \*p_whisper, audio_buffer_t audio, int task_code, std::vector\<std::string\> &recognized_text);The details are as follows.
| Function Name: speech_recognition_run | |
| Header File | speech_recognition.h |
| Input Parameter | p_whisper: speech recognition handle |
| Input Parameter | audio:audio to be recognizedinformation |
| Input Parameter | task_code: speech recognition task |
| Input Parameter | recognized_text:Speech Recognition Result |
| Return Value | Return value on success: 0 |
| Return value on failure: -1 | |
| Notes | None |
3.4 Speech RecognitionRelease Function
The speech recognition release function prototype is as follows.
int speech_recognition_release(rknn_whisper_t \*p_whisper);The details are as follows.
| Function Name:speech_recognition_release | |
| Header File | speech_recognition.h |
| Input Parameter | p_whisper: speech recognition handle |
| Return Value | Return value on success: 0 |
| Return value on failure: -1 | |
| Notes | None |
4. Speech Recognition Algorithm Sample
The sample directory is Demos/algorithm-speech_recognition/test-speech_recognition.cpp, and the operation flow is as follows:
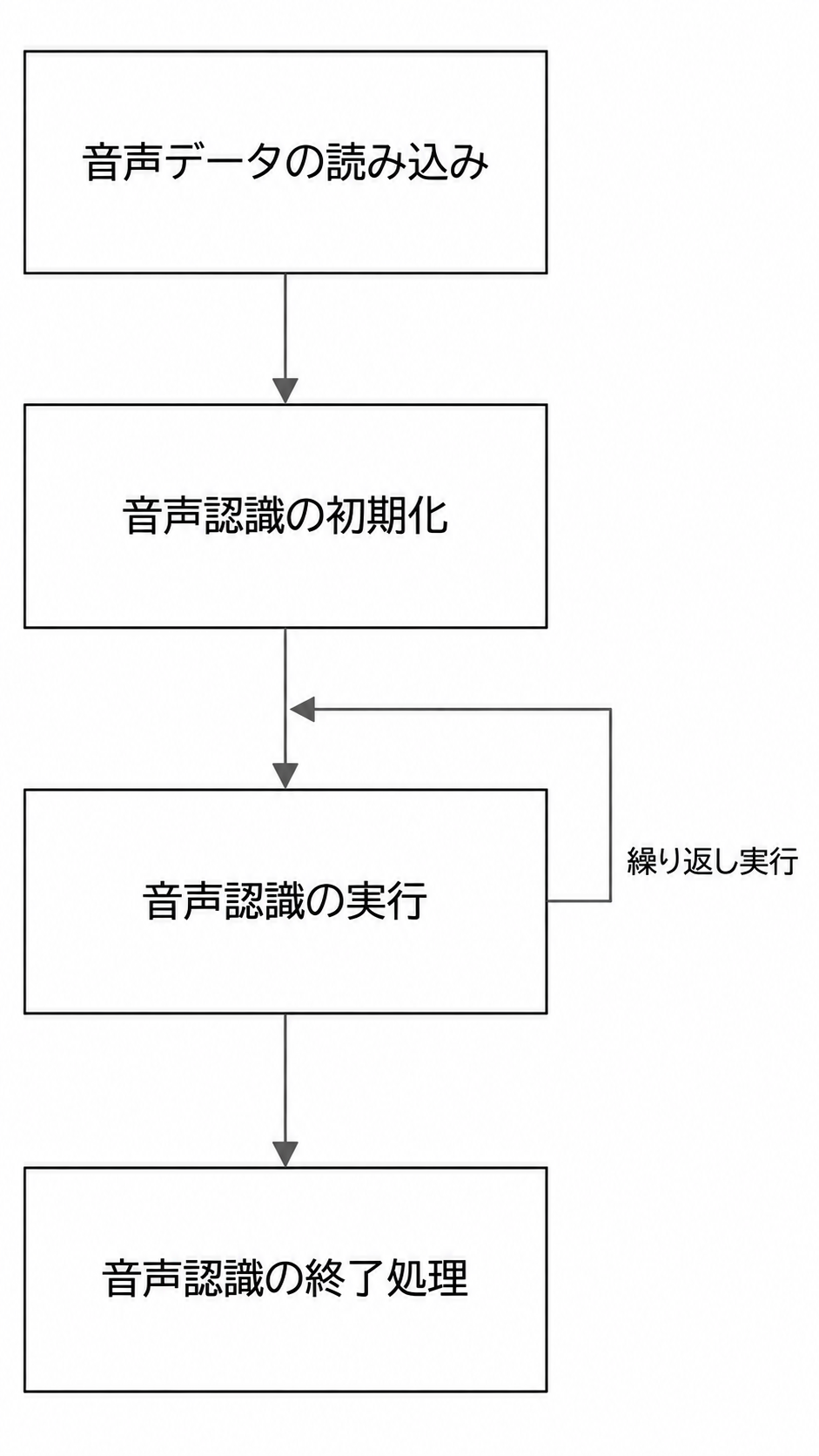
Figure 4-1 Speech Recognition Algorithm Processing flow
The reference sample is as follows.
#include <iostream>#include <stdlib.h>#include <stdio.h>#include <string.h>#include <time.h>#include <string>#include <vector>#include <fstream>#include <sstream>#include <unordered_set>#include <unordered_map>#include <algorithm>#include "sndfile.h"#include "speech_recognition.h"#include "audio_utils.h"
static bool is_base64_char(char c){ return (c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '+' || c == '/' || c == '=';}
static bool looks_like_base64_token(const std::string &input){ if (input.empty() || (input.size() % 4) != 0){ return false; } for (char c : input){ if (!is_base64_char(c)){ return false; } } return true;}
static std::string base64_decode_token(const std::string &input, bool *ok){ static const std::string table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; std::string out; int val = 0; int valb = -8;
if (!looks_like_base64_token(input)){ *ok = false; return input; }
for (unsigned char c : input){ if (c == '='){ break; } int d = (int)table.find(c); if (d == (int)std::string::npos){ *ok = false; return input; } val = (val << 6) + d; valb += 6; if (valb >= 0){ out.push_back(char((val >> valb) & 0xFF)); valb -= 8; } } *ok = true; return out;}
static std::string trim_copy(const std::string &s){ size_t b = s.find_first_not_of(" \t\r\n"); if (b == std::string::npos){ return ""; } size_t e = s.find_last_not_of(" \t\r\n"); return s.substr(b, e - b + 1);}
static bool load_base64_vocab_tokens(const char *vocab_path, std::unordered_set<std::string> &token_set, std::vector<size_t> &token_lengths){ std::ifstream ifs(vocab_path); if (!ifs.is_open()){ return false; }
std::string line; std::unordered_set<size_t> length_set; while (std::getline(ifs, line)){ line = trim_copy(line); if (line.empty()){ continue; }
// Expected format: "<id> <token>". Keep compatibility with token-only lines too. std::string token; size_t pos = line.find_first_of(" \t"); if (pos == std::string::npos){ token = line; } else{ token = trim_copy(line.substr(pos + 1)); }
// Skip Whisper special tokens such as <|ja|> and non-base64 plain tokens. if (looks_like_base64_token(token)){ token_set.insert(token); length_set.insert(token.size()); } }
token_lengths.assign(length_set.begin(), length_set.end()); std::sort(token_lengths.begin(), token_lengths.end(), std::greater<size_t>()); return !token_set.empty();}
static bool decode_concatenated_base64_vocab(const std::string &input, const std::unordered_set<std::string> &token_set, const std::vector<size_t> &token_lengths, std::string &decoded_output){ decoded_output.clear(); if (input.empty() || token_set.empty() || token_lengths.empty()){ return false; }
size_t pos = 0; bool decoded_any = false;
while (pos < input.size()){ bool matched = false;
for (size_t len : token_lengths){ if (pos + len > input.size()){ continue; } std::string piece = input.substr(pos, len); if (token_set.find(piece) != token_set.end()){ bool ok = false; std::string decoded = base64_decode_token(piece, &ok); if (ok){ decoded_output += decoded; pos += len; matched = true; decoded_any = true; break; } } }
if (!matched){ // If the raw output contains non-base64 plain text, preserve it instead of failing hard. decoded_output.push_back(input[pos]); pos++; } }
return decoded_any;}
static std::string build_raw_output_text(const std::vector<std::string> &recognized_text){ std::string raw; for (const auto &str : recognized_text){ raw += str; } return raw;}
static std::string build_output_text(const std::vector<std::string> &recognized_text, bool decode_base64_vocab, const std::unordered_set<std::string> &token_set, const std::vector<size_t> &token_lengths){ if (!decode_base64_vocab){ return build_raw_output_text(recognized_text); }
std::string output;
// Case 1: recognized_text keeps token boundaries. Decode each token independently. if (recognized_text.size() > 1){ for (const auto &str : recognized_text){ bool ok = false; std::string decoded = base64_decode_token(str, &ok); output += ok ? decoded : str; } return output; }
// Case 2: speech_recognition_run has already concatenated Base64 token strings // into one string, such as "MQ==Mg==Mw==". Decode by matching against the vocab. std::string raw = build_raw_output_text(recognized_text); std::string decoded_concat; if (decode_concatenated_base64_vocab(raw, token_set, token_lengths, decoded_concat)){ return decoded_concat; }
// Fallback: try to decode it as a single Base64 token. bool ok = false; std::string decoded = base64_decode_token(raw, &ok); return ok ? decoded : raw;}
int main(int argc, char **argv){ if (argc != 6 && argc != 7){ printf("%s <encoder_path> <decoder_path> <filter_path> <vocab_path> [task(en/cn/zh/ja/jp)] <audio_path>\n", argv[0]); printf("Default task: ja (Japanese recognition)\n"); printf("Example default Japanese: %s speech_encoder.model speech_decoder.model filters.txt JP.txt 1-10-1_JP.wav\n", argv[0]); printf("Example Japanese: %s speech_encoder.model speech_decoder.model filters.txt JP.txt ja 1-10-1_JP.wav\n", argv[0]); printf("Example Chinese: %s speech_encoder.model speech_decoder.model filters.txt CN.txt cn 1-10-1_CN.wav\n", argv[0]); printf("Example English: %s speech_encoder.model speech_decoder.model filters.txt EN.txt en sample_EN.wav\n", argv[0]); return -1; }
const char *p_encoder_path = argv[1]; // エンコーダモデルパス const char *p_decoder_path = argv[2]; // デコーダモデルパス const char *p_filter_path = argv[3]; // フィルタスペクトル const char *p_vocab_path = argv[4]; // 語彙ファイル const char *p_task = "ja"; // 認識言語(デフォルト:ja) const char *p_audio_path = NULL; // 認識対象音声
if (argc == 6){ p_audio_path = argv[5]; } else{ p_task = argv[5]; p_audio_path = argv[6]; }
int task_code = 0; std::vector<std::string> recognized_text; bool decode_base64_vocab = false;
// Tokenizer の事前定義制御シンボル(Whisper 言語トークン) if (strcmp(p_task, "en") == 0){ task_code = 50259; // <|en|> } else if (strcmp(p_task, "cn") == 0 || strcmp(p_task, "zh") == 0){ task_code = 50260; // <|zh|> decode_base64_vocab = true; } else if (strcmp(p_task, "ja") == 0 || strcmp(p_task, "jp") == 0){ task_code = 50266; // <|ja|> decode_base64_vocab = true; } else{ printf("\n\033[1;33mUnsupported recognition task: %s. Please specify <task> as en, cn/zh, or ja/jp. If omitted, ja is used by default.\033[0m\n", p_task); return -1; }
std::unordered_set<std::string> base64_token_set; std::vector<size_t> base64_token_lengths; if (decode_base64_vocab){ if (!load_base64_vocab_tokens(p_vocab_path, base64_token_set, base64_token_lengths)){ printf("\n\033[1;33mWarning: failed to load Base64 vocab tokens from %s. Output may remain encoded.\033[0m\n", p_vocab_path); } }
printf("Recognition task: %s, language token id: %d\n", p_task, task_code);
// 音声を読み込み、音声データを処理します audio_buffer_t audio; int ret = read_audio(p_audio_path, &audio); if (ret != 0){ printf("read audio fail! ret=%d audio_path=%s\n", ret, p_audio_path); return -1; } if (audio.num_channels == 2){ ret = convert_channels(&audio); } if (audio.sample_rate != SAMPLE_RATE){ ret = resample_audio(&audio, audio.sample_rate, SAMPLE_RATE); }
// speech recognition を初期化します rknn_whisper_t whisper; ret = speech_recognition_init(p_encoder_path, p_decoder_path, p_filter_path, p_vocab_path, &whisper); if (ret != 0){ printf("speech_recognition_init fail! ret=%d\n", ret); return -1; }
int iter = 0; for (int i = 0; i < 5; i++) { clock_t start = clock();
recognized_text.clear(); // speech recognition による音声認識 ret = speech_recognition_run(&whisper, audio, task_code, recognized_text); if (ret != 0){ printf("speech_recognition_run fail! ret=%d\n", ret); break; }
clock_t end = clock(); double infer_time = ((double)(end - start)) / CLOCKS_PER_SEC;
std::string raw_output_text = build_raw_output_text(recognized_text); std::string output_text = build_output_text(recognized_text, decode_base64_vocab, base64_token_set, base64_token_lengths);
// decoded output std::cout << "\nspeech recognition output: " << output_text << std::endl;
// raw output is useful for diagnosing Base64 vocab and decoder behavior. if (decode_base64_vocab){ std::cout << "speech recognition raw output: " << raw_output_text << std::endl; std::cout << "recognized_text pieces: " << recognized_text.size() << std::endl; }
float audio_length = audio.num_frames / (float)SAMPLE_RATE; // sec audio_length = audio_length > (float)CHUNK_LENGTH ? (float)CHUNK_LENGTH : audio_length; float rtf = infer_time / audio_length; printf("%d, Real Time Factor (RTF): %.3f / %.3f = %.3f\n", iter++, infer_time, audio_length, rtf); }
// speech recognition を解放します speech_recognition_release(&whisper); return 0;}